!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
CHANCE News 10.06
May 21, 2001 to July 4, 2001
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Prepared by J. Laurie Snell, Bill Peterson, Jeanne Albert, and Charles Grinstead, with help from Fuxing Hou and Joan Snell.
We are now using a listserv to send out Chance News. You can sign on or off or change your address at this Chance listserv.This listserv is used only for mailing and not for comments on Chance News. We do appreciate comments and suggestions for new articles. Please send these to:
jlsnell@dartmouth.edu
Back issues of Chance News and other materials for teaching a Chance course are available from the Chance web site.
Chance News is distributed under the GNU General Public License (so-called 'copyleft'). See the end of the newsletter for details.
Is this the earliest reference to such an observation?Speaking of origins of quotes, a member of the Science Writer listserv asked if anyone knew the actual quote from Einstein regarding God does not role dice? Another member replied:
====================================================
When
the Okies migrated from Oklahoma to
California,
they raised the average IQ's of both
states.
Will Rogers
====================================================
Does anyone know a reference for
this quote?
Since Einstein spent many
years debating quantum mechanics and the probabilistic interpretation, you
can probably find a variety of versions of the quotation. The most famous,
and most important, is from a letter Einstein wrote to Max Born, dated Dec.
4, 1926. Einstein told him: Quantum mechanics is
certainly imposing. But an inner Contents of Chance News
10.06 3. Marilyn on the risk of flying. 4. How colleges reject
the top applicants. 5. Study says placebo
effect is more myth than science. 6. Getting random sequences from nature. 7. U.S. death penalty
system not biased, Ashcroft declares. 8. A review of The Lady Testing Tea. 9. Reviews of "Lies Damned Lies and Statistics" and "It Ain't
Necessarily So." <<<========<<
>>>>> ==============> If his statistical correlation
is better than the statistical average, Researchers have found that
men in urban areas are 62 >>>>>=============> Our readers would also enjoy
Paulos' June and July ABC news columns. In his June column John discusses Simpson's paradox and a
course load paradox. In his July column he gives an interesting explanation for
why the correlation of SAT scores to freshman grades appears to be lower than it
actually is.
>>>>>=============> I believe it. In fact, I
have long believed that referring to a well- known
statistical observation that a patient who feels particularly terrible one
day will almost invariably feel better the next day, no matter what is done
no matter what is done for him. (1) Tom Wallsten suggest that
the New York Times remarks about what Donald Berry said should be considered for
a Forsooth item. What did he have in mind?
voice tells me that it is not yet the
real thing. The theory
says a lot, but does not really bring us any
closer to the
secret of the 'old one.' [Der Alte.] I, at any rate,
am
convinced that He
is not playing at dice.
Here are two Forsooth items from the May 2001 issue of RSS
News.
then his hypothesis warrants
investigation,' said Dr Chong
[Universiti Sains Malaysia's Astronomy
Clubs adviser, with
reference to an observation which suggested a
relation
between UFO sightings and earthquakes].
Straits Times (Singapore)
28 February 2001
per cent more likely to die than those in the
country,
small towns or suburbs.
The Daily Telegraph
January
2001
<<<========<<
John Paulos noticed a Forsooth item in a
recent column of William Safire. Safire assumes that Bush will run in 2004 and
gives his odds for each of 10 possible democratic presidential candidates being
Bush's opponent. John observes that his odds give a probability of 168% that one
of the ten will be Bush's opposition. You can find Safire's column and John's
commentary here.
<<<========<<
Ask
Marilyn.
Parade Magazine, 27 May 2001,
16
Marilyn vos Savant
A reader writes: "My husband flies at least 100
times a year. I know the odds of an accident are the same for every flight, but
I say he is more likely to be involved in one than someone who flies less. He
insists this in not an actual risk for him."
Marilyn responds "I agree
with both of you. If your husband flies 100 times a year, he runs 100 times the
risk of someone who flies only once a year. But his risk is still statistically
insignificant. Flying is amazingly safe."
DISCUSSION
QUESTIONS:
(1) In Chance
News 8.09, we summarized
Arnold Barnett's Chance Video lecture "Risks in Everyday Life," which estimated
the risk of death by flying to be about 1 in 7 million. Consider taking 100
flights, each of which exposes you to this risk. Marilyn's argument suggests
that your cumulative risk is 1 in 70 thousand. Is this approximately correct?
What assumptions are you making?
(2) What do you think Marilyn means by
the phrase "statistically insignificant"? Suppose someone flies 100 times a year
over a 30-year career. Would you characterize this person's cumulative risk as
"statistically insignificant"?
(3) How reasonable is it to assume that
"the odds of an accident are the same for every
flight?"
<<<========<<
>>>>>=============>
Glass
floor : How colleges reject the top
applicants--and boost their status.
The Wall Street Journal, 29 May 2001,
A1
Daniel Golden
In the "old days," according to this story, colleges
accepted the applicants with the best credentials, and wait-listed the less
well-prepared. In the last decade, a new trend has emerged. Applicants perceived
as "overqualified", and thus likely to choose other institutions, have been
placed on the waiting list, while admission is offered to students who are
objectively less qualified but more likely to enroll. This practice has become
especially common among schools perceived as just below the top tier. The
article begins with the example of Franklin and Marshall College in
Pennsylvania, which last year rejected 140 of its top applicants. These students
had not interviewed with the school or otherwise shown real interest in
attending, and past admissions experience suggested that they were not likely to
enroll.
Are such schools just being realistic, or are they playing a
numbers game with their admissions scores? That is the question raised by the
article, which points out that acceptance rate and admissions "yield" (the
percentage of those admitted who ultimately enroll) counts for 1/4 of the
selectivity score in the popular US News College Rankings. The article estimates
that changes in these numbers could move a school up or down several positions
in the rankings. Emory University in Atlanta, often used as a back-up school by
Ivy League applicants, is cited as a big winner in efforts to improve yield.
Over the last ten years, Emory has improved its yield from 23% to 33% by giving
preference to candidates who visit the campus, interview with the school, or
meet with representatives at college fairs.
There is no question that
colleges are receiving more applications each year, owing in part to increasing
national competition for admission. To manage the process, schools are turning
to admissions consulting firms, who apply sophisticated statistical models that
use intended major, extracurricular activities, and other demographic variables
to predict the chance that an applicant will enroll if accepted. In some of
these models, when an applicant's test scores exceed the median for the school,
the predicted chance of enrolling goes down.
The new policies may have
some unfortunate side effects. A highly qualified applicant who is not accepted
at a top-ranked school may find herself also rejected by the second-tier schools
who perceive her as overqualified. According to the article, colleges are now
getting angry phone calls from parents and guidance counselors of students
stranded in this strange new middle ground.
DISCUSSION
QUESTIONS:
(1) How do you think the article estimated the effect of yield
on the position in the US News ranks? You can find more detail about the formula
on the US News web
site.
(2)
Besides improving the yield numbers, what other benefits can you see to the
strategy favoring applicants with demonstrated interest in the school? Can you
think of any other
risks?
<<<========<<
>>>>>=============>
Placebo Placebo effect is more
myth than science, study says.
The New York Times, 24 May 2001, A20
Gina
Kolata
Is the placebo powerless? An analysis of clinical trials comparing
placebo with no treatment.
New England Journal of Medicine, 344 (24 May
2001): 1594-1602.
Asbjorn Hrobjartsson and Peter C. Gotzsche
The
powerful placebo and the Wizard of Oz.
New England Journal of Medicine, 344
(24 May 2001): 1594-1602.
John C. Bailar III
The use of placebo
controls in randomized experiments is familiar to all students of statistics. A
more radical use of placebo was advocated in a New York Times Magazine article
entitled "The Placebo Prescription," which we summarized for Chance News 9.02. The central idea there was that the placebo
effect observed in clinical trials could be harnessed as a legitimate medical
treatment. But now two Danish researchers have reported in the New England
Journal of Medicine that the therapeutic value of placebos is essentially a
myth.
Dr. Hrobjartsson is quoted in the New York Times as observing that
no published research had made the distinction between the placebo effect and
the natural variations in symptoms as a disease runs its course. He and his
colleague, Dr. Gotzsche, therefore undertook an extensive literature review to
find studies which included both a placebo group and an untreated group. If the
placebo effect is real, they reasoned, then it ought to show up in comparisons
of the placebo group with the untreated group. Ultimately, they identified 114
suitable studies, involving a total of 7500 patients and 40 different medical
conditions.
A number of categories of studies had to be distinguished.
Some involved binary responses (the patient's condition either improved or did
not), while others had continuous responses. In some, the response was based on
the patients' subjective perceptions, whereas others measured physiological
responses. Also, three types of placebos were distinguished: pharmacological
(such as pills), physical (such as manipulation), and psychological (such as a
conversation).
For binary outcomes, there was no significant difference
between placebo and no treatment. Considering subjective and objective responses
separately gave results similar to the overall results. On the other hand, for
continuous outcomes there was a significant difference overall between placebo
and no treatment groups. However, when the continuous results were broken down
by response type, the subjective responses showed a significant difference,
while the objective responses did not. Furthermore, it was found that the effect
decreased as the size of the trials increased. The researchers suggested a
possible bias in the smaller trials: the patients' subjective reports of
improvement in smaller studies may reflect a desire to please their doctors.
Patterns similar to the above were observed when pharmacological, physical and
psychological placebos were considered separately.
Hrobjartsson and
Gotzsche conclude that placebo treatment has no use beyond clinical trials
experiments. In an editorial accompanying the research article, John Bailar
compares the power of the placebo to the power of the Wizard of Oz, which
depended on no one looking behind the curtain. Still, Bailar seems uncomfortable
with a complete rejection of placebos. While he calls for careful scrutiny of
any proposed uses, he holds out some hope that they may still be useful in
specific settings, such as pain relief.
The New York Times article
presents interesting observations from other experts. We read: Dr. Donald Berry, a statistician at the M.
D. Anderson Cancer Center in Houston, said
the placebo effect is nothing more than a
regression effect,"
(2) Freedman, and also Bailar
to some extent, appear to be arguing that placebos might work in specific
settings, even if no general "placebo effect" turns up in a comprehensive
examination of all applications. Do you agree? How do you think Hrobjartsson and
Gotzsche might respond?
(3) In his editorial, Bailar notes that "...the
research setting, with its generally intense methods of observation and precise
measurement of outcomes, may obscure a real effect of placebo that would be
evident in nonresearch settings. However, it is not clear how one could study
and compare the effects of placebo in research and nonresearch settings, since
that would of course require a research study." Do you see any way out of this
paradox?
<<<========<<
>>>>>=============>
Connoisseurs of Chaos Offer A Valuable Product:
Randomness.
New York Times 12 June, 2001
George
Johnson
Randomness as a
resource.
American Scientist, July-August 2001
Brian Hayes
These are two excellent articles on how random numbers have used and how they have been generated from the past to the present. As we learn from the Times article, there is a long history to ways to generate random sequences. Weldon tried rolling dice but then Karl Pearson showed that there to be too many 5's and 6's. A similar problem occurred when Tippetts tried to randomly select numbers from a bag with a thousand cards. Fisher and Yates used two decks of playing cards and again there were too many sixes. Then came the publication of "A million random numbers" by Rand Corpration. Finally, the computer produced pseudo-random numbers. While statisticians were experimenting, mathematicians were trying to give a mathematical definition of a random sequence. After many failures there appears to be some satisfaction with the modern Chaitin-Kolmogorov defintion which states that a sequence is random if the length of the shortest program to produce the first n digits is essentially as long as the n digit sequence itself. But by their definition any sequence that you can produce by an algorithm which includes pseudo-random sequences cannot be random. Thus someone who really needs truly random sequences has to turn elsewhere.
If we believe in quantum physics, the natural place to turn is nature itself. The Times article discusses three web sites that will produce random sequences for you by physical processes. The first site Hotbits generates random digits by using radioactive decay. The second site Random.org uses a radio tuned between stations to obtain atmospheric noise. The third site called Lavarand is based on the idea that a lava lamp is a chaotic system. Each of these sites has a good explanation of how their system works. Random.org has a general discussion of random numbers and links to other sites that provide such information.
None of these web solutions are yet able to produce large numbers of random sequences fast enough for many of the simulations we are used to carrying out. However, according to the American Scientist article, there are hardware solutions that produce random numbers using thermal noise that can be plugged into your computer. Also such a generator is part of the newer Intel Pentium processors.
The American Scientist article has more details on some of the modern applications of random numbers especially in the field of cryptography.
DISCUSSION QUESTION:
Even sequences that are produced by physical processes sometimes fail to pass statistical tests and have to be modified by mathematical methods. For example, from the FAQ page of the Random.org site we read:
A digital camera takes a picture of some Lava Lite lamps, the digital output
of that image is fed into various number mungers and kablam! you have a
bona fide random number.
Why do you think the number
mungers are necessary? Do you think this is cheating?
<<<========<<
>>>>>=============>
Mike
Olinick suggested the following story.
Group seeks moratorium on federal
executions; Bush administration accused of stalling study on racial bias as date
nears for inmate Garza.
The Washington Post, 4 June 2001, A2
William
Claiborne
U.S. death penalty system not
biased, Ashcroft declares; Study finds disparities in prosecution.
The
Washington Post, 7 June 2001, A29
Dan Eggen
Opponents of the death penalty
charge that its imposition in federal cases reflects racial and geographical
biases. Fourteen of the twenty prisoners now on federal death row are
minorities, and the majority of death penalty cases arise in conservative
states. The advocacy group, Citizens for a Moratorium on Federal
Executions, is asking
that all federal executions be put on hold until these problems can be further
investigated.
The issue is pressing because a Mexican-American inmate,
Juan Raul Garza, is scheduled to be executed on June 14 for his role in several
murders related to drug-trafficking. The first article presents the Citizens
group's charge that the Bush administration is delaying the release of a pending
death penalty study in order to expedite Garza's execution. The study was begun
by Attorney General Janet Reno during the Clinton administration, and President
Clinton had granted Garza a stay of execution while the study was being
conducted.
By the time of the second article, the study had been
released. Attorney General John Ashcroft maintained that it shows no evidence of
racial bias. Echoing statements made by George W. Bush in defense of the Texas
death penalty, Ashcroft asserted that there is no doubt about the guilt of any
of the current federal death row inmates. He also pointed out that blacks and
Hispanics are less likely than whites to face capital punishment after being
charged. But critics counter that minorities are more likely to be charged with
capital crimes in the first place, and that this disparity leads to the
preponderance of minorities on death row.
The study did find that whites
were more than twice as likely as blacks to avoid the death penalty through plea
bargains. While conceding that such bargains might need more careful attention
in the future, Ashcroft tried to downplay the finding as a "minor statistical
discrepancy."
Bruce Gilchrist, who is one of Garza's attorneys, still
feels that the study has been released too late to help in appeals for his
client. Moreover, he adds that the study fails to provide any real insight into
what is going wrong with the system. Further concerns from the Garza defense
team are presented in a recent New York Times article ("Lawyers trying to stop
execution cite flaws in bias report," 13 June, 2001, A24). There they criticize
the study for ignoring potential death penalty cases in which the death penalty
was not sought.
DISCUSSION QUESTIONS:
(1) The New York Times
article summarizes the study's findings by saying that "in nearly 80 percent of
the cases in which prosecutors sought the death penalty, the defendant was a
member of a minority group and nearly 40 percent of death penalty cases
originated in nine of the states." Does the second figure necessarily show
geographical bias? What else would you like to know?
(2) If 80 percent of
capital cases have a minority defendant, can it still be true, as Ashcroft,
asserts, that blacks and Hispanics are less likely to face capital punishment
after being
charged?
<<<========<<
>>>>>=============>
We read three new books that will be of
interest to your readers. The first is sure to make you feel better about
statistics but then the other two might make you feel worse.
The Lady Tasting Tea : How statistics revolutionized science in
the twentieth century.
W H Freeman & Co. May 2001
David Salsburg
David Salsburg is a statistician who has retired from a career which combined teaching in several colleges and universities and doing research for the Pfizer pharmaceutical company. He has written a lively popular account of the development of twentieth century statistics. The leading actor in the book, not surprisingly, is R. A. Fisher.
Reading this book one can appreciate a remark made by Brad Efron on its cover:
If
scientists were judged by their influence on science, then Fisher would
rank with Einstein and Pauling at the top
of the modern ladder.
To make his characters come to life Salsburg has used stories he learned from interviews with others who were there. He also acknowledges help from the fine series of interviews with statisticians that has appeared in Statistical Science.
One problem with relying on
interviews is that people's memories are not so reliable sometimes. This leads
to a number of small errors such as: Fisher didn't propose testing the lady's
ability to tell whether the milk was put in first or not, it was Wiliam Roach
(assuming we believe Joan Fisher Box), Feller's first job when he came to
America was not at Princeton but rather at Brown, and Ville, not Levy, was the
first to use the word Martingale for a chance process. But who cares? Its the
story that we want and Salsbury tells a great
story!
<<<========<<
>>>>>=============>
Damned
Lies and Statistics: untangling numbers from the media,
politicians and activists.
University of California Press, May 2001
Joel
Best
It
Ain't Necessarily So :
How media make and unmake the scientific picture of reality.
Rowman &
Littlefield; April 2001
David Murray, Joel Schwartz, and S. Robert Lichter
We are sure that methods for lying with statistics were well known to the Greeks, but the art of doing so was first popularized in modern times by the charming book How to lie with statistics by Darrell Huff. More recently we have had Cynthia Crossen's wonderful book Tainted Truth , which told us how statistics gets contaminated when sponsored by industries, especially pharmaceutical companies.
Now we have two new books that tell us how easy it is to mangle statistics related to public policy decisions such as AIDS, Gun laws, domestic violence, and the census. These two books are remarkably similar and you can hear the two authors amiably discussing their books on NPR Science Friday. June 08, 2001.
Joel Best, author of "Damned Lies and Statistics," is professor of criminal justice at the University of Deleware. "It Ain't Necessarily So" has three authors, Murray, Schwartz and Lichter.. David Murray is director of of the statistical assessment service (STATS) and adjunct professor at Georgetown University. STATS publishes the monthly newsletter Vital STATS which, like Chance News, discusses statistical issues in the news. You might like to look at the June issue where you will find a discussion of the placebo study mentioned above and several other interesting current articles that we have not discussed. Joel Schwartz is senior adjunct fellow at the Hastings Institute, and S. Robert Lichter is president of the Center for Media and Public Affairs in Washington and also of STATS.
Both books identify several
basic kinds of errors commonly made and then discuss these in the context of
recent studies or news reports. We consider first Best's
book.
The
Introduction discusses the author's candidate for the the worst social
statistical social statistic ever: Every year since 1950, the number of American
children gunned down has doubled. Chapter 1 discusses the importance of
social statistics. The remaining chapters treat specific kinds of problems.
The authors of both books emphasize that almost anyone who uses statistics to support a public policy has his own political agenda. And it is also natural to ask how much does bias affect these authors' critiques. In a review of "It Ain't Necessarily So" in Salon, July 2, 200, writer David Appell argues that the authors' conservative backgrounds lead to biased discussions of the the way news is reported, especially those new items relating to issues where conservatives have an active interest. Appell chooses, as an example, the authors' criticism of the coverage of a study of Camille Parmesan's reported in "Nature" in August 1996. This was a study of the extinction rates of local populations of a western butterfly, the Edith's checkerspot. Parmesan observed that, overall, the butterfly had moved north by about one hundred miles and suggested that this was evidence of global warming. Appell makes a pretty good argument that the critique is biased but then maybe he's a flaming liberal! However, we always say that "you should look at the data." So, since almost all the articles discussed in the book are available from Lexis Nexis, readers of "It Ain't Necessarily So" might enjoy reading the news articles along with the critiques to make up their own minds.
Mr. Prewitt wistfully suggests a nationwide numeracy campaign. The
country talks about improving literacy, he says. But most of the public
conversation is about numbers: statistics,trend lines, social indicators.
Perhaps the country should take numeracy as seriously as literacy if it
wants intelligent public discourse.
These books should make a significant contributions to statistical literacy.
(2) If you were advising an
editor of a newspaper on how to improve their reporting of statistical data what
would you recommend?
<<<========<<
>>>>>=============>
We usually do not go into the technical details of a
study that we discuss in Chance News but decided that it might be fun to try
this. We chose the study "Survival in academy award-winning actors and actresses,"
Annals of Internal Medicine, Vol. 134, No. 10, by Donald A Redelmeir
and Sheldon M. Singh discussed in Chance News 10.05. Redelmeier was also the lead author of the
interesting study on the danger of using a cell phone while driving, discussed
in Chance News 6.03 and 6.10 and in an article "Using a car phone like
driving drunk?" in Chance Magazine, Spring 1997.
A good description of how the Kaplan-Meier test is carried out can be found in Chapter 12 of the British Medical Journal's on-line statistic book "Statistics at Square One."
The Kaplan-Meier test requires that we construct a life table for Oscar winners and the control group. We start by reminding our readers how Life Tables are constructed for the US population. The most recent US Life Tables can be found in CDC's National Vital Statistics Report Volume 58, Number 18 and are based on 1998 data. Life tables are given by sex and gender and also for the total US population. The following table is from the first 10 rows of the Life Table for the 1998 US population.
Proportion
dying during
age interval
Number living
at beginning of
age interval
Life expectancy
at beginning of
age interval
Table 1. From the 1998 US Population Life Table.
The first column indicates the first 10 age intervals.
To determine the life expectancy of a newborn baby we need only sum l(x) for all x. (Recall that for a discrete random variable X the expected value of X can be computed by the sum over all x of Prob(X >= x)). To find the life expectancy for a person who has reached age x we add the values of l(x)/l(t) for t greater than or equal to x. From the table we see that the life expectancy for a person at birth is 76.7 while for a person who has survived 9 years it is 69.4 making a total life expectancy of 79.4. Thus there is a 2.7 year bonus for having survived 9 years. You can view the entire Life Table here and check your own bonus. We have 10 year bonus for surviving so long but, alas, only a 10.7 year additional expected lifetime.
For a discussion of the technical problems in producing and interpreting Life Tables see the article "A method for constructing complete annual U.S. life tables" by R. N. Anderson.
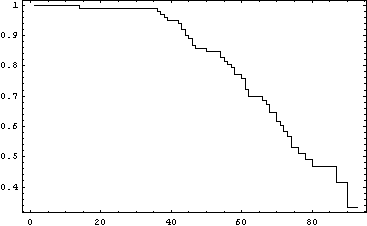
Dr. Relemeier provided us with the data needed to carry out the Kaplan-Meier test. In Table 1 we show the first 10 entries in his data set for the members of the control group:
when died or left the study0 means died in year x
1 means lost to the study in year x
In column 4 we put the number n(x) of Oscar winners known to be alive at the beginning of year x.
Case The year x that an Oscar winner died or left the study A 0 means the winner died in year x and a 1 means the winner was lost to the study in year x The number n(x) of Oscar winners known to be alive at the beginning of year x The number d(x) of Oscar winners who died in year x The proportion q(x) of those life to the xth year who survived this year The proportion l(x) of Oscar winners who survived at least x years 0 1 1 27 1 30 0 1 1.000 2 37 1 29 0 1 1.000 3 38 1 28 0 1 1.000 4 45 1 27 0 1 1.000 5 50 1 26 0 1 1.000 6 51 1 25 0 1 1.000 7 54 1 24 1 23/24 0.958 8 54 1 9 54 0 10 57 1 21 1 20/21 0.913 11 57 0 12 61 0 19 2 17/19 0.817 13 61 0 14 63 1 17 0 1 0.817 15 65 0 16 1 15/16 0.766 16 69 1 15 0 1 0.766 17 73 1 14 0 1 0.766 18 73 1 19 74 1 12 0 0.766 20 75 1 11 0 0.766 21 77 0 10 1 8/10 0.612 22 77 0 0.612 23 78 0 8 1 7/8 0.536 24 81 0 7 1 6/7 0.459 25 82 1 6 0 0.459 26 84 0 5 1 4/5 0.367 27 85 0 4 1 3/4 0.276 28 92 1 3 0.276 29 93 0 2 1 1/2 0.138 30 96 1 1 1 1 0.138
Plotting l(x) we obtain the following survival curve for the Oscar winners.
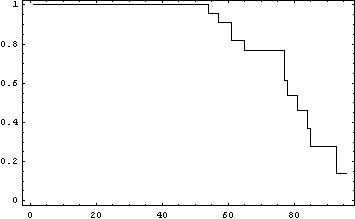
Figure 2 The Survival curve for the sample of Oscar winners
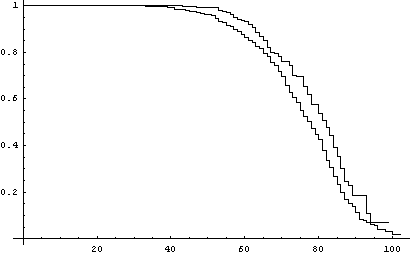
Putting the two together for comparison we obtain:
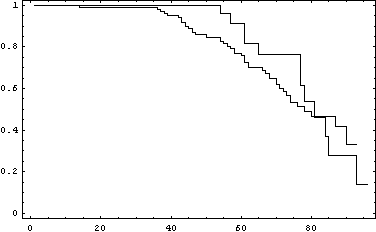
Figure 4 Survival curve for the sample of 30 Oscar winners and 100 controls
Putting the two together for comparison we obtain:
We say an event happened in age year x if either at least one subject died or was lost to the study during this year.For each group and each age year we count the number still being followed at the beginning of the year and the number of deaths during this year. For example, in our sample we find that in the age year 61 we were still following 19 Oscar winners 2 of whom died in this year. For the control group we were still following 65 controls one of whom died this year. Thus there was a total of 84 still being followed at the beginning of age year 61 and a total of 3 deaths during this year. Now, under the hypothesis that there is no difference between Oscar winners and the controls, these 3 deaths should be randomly chosen from the 84 people still being followed. Thus we can imagine an urn with 84 balls, 19 marked O for Oscar winner and 65 marked C for controls. Then father death chooses three balls at random from this urn to determine the deaths. Then the number of the number of deaths chosen from the Oscar winners group has a hypergeometric distribution. The probability that any particular death is an Oscar Winner is 19/84 so the expected number of Oscar winners deaths in year 61 is 3*(19/84) =..679. The observed number o was 1. We also need to calculate the variance of the number of deaths among the Oscar winners. This is more complicated because the variance for the multinomial distribution is complicated.
Assume that you have n balls in
an urn, k are red and and n-k are black. Then if you draw m balls at random
the expected number of red balls is
e = m(k/n)
and the variance is
v
= ( m*(k/n)*(n-k)/n)*((n-m)/(n-1)).
In our example the red balls are Oscar winners so the variance for the number of Oscar winners who died in the 61th year is
v = 5*(19/84)*(65/84)*(81/83)= .854
Then to carry out the rank-order test we do the above calculations for each age year for a particular group. We chose the Oscar winners. Let O be the sum of the observed number of Oscar winners who died in each year, E the sum of the expected values over all years and V the sum of the variances over all years, Then the statistic
S = ((O-E))/sqrV
will, by the Central Limit theorem, be approximately normal so S^2 will have approximately a chi-square distribution with 1 degree of freedom. Note that in summing the variances we are assuming that the observed numbers of Oscar winners who die in different years are independent. This is true because we are conditioning on knowing the number in each group that we are still watching and the total number of deaths for a given year. These determine the distribution of the number of Oscar winners who die in this year under our assumption that there is no difference between the two groups.
Using our program to carry out these calculations for the data for this study we found S^2 = 9.1246. The probability of finding a chi-squared value greater than this is .0025 so this indicates a significant difference between the Oscar winners group and the control group.
To check our program we carried out the calculations for the Kaplan-Meier procedure, as did the authors, using the SAS statistical program. SAS yielded the same survival curves as our program and for the significance tests SAS reported:
Test Chi-Square Degrees of freedom Prob >
Chi-Square
Thus the log-rank test agreed with our calculation. SAS also provided two other tests that might have been used both of which would result in rejecting the hypothesis that there was no difference between the two groups. This ends our saga
<<<========<<
>>>>>=============>
Copyright (c) 2001 Laurie Snell
This work is freely redistributable
under the terms of the GNU
General Public License published
by the Free Software Foundation.
This work comes with ABSOLUTELY NO WARRANTY.
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!CHANCE News 10.06
May 21, 2001 to July 4, 2001!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!